During my time at Netdata, I initiated a long-term documentation
standardization project after uncovering inconsistencies in a detailed
content audit. I created page-level markdown templates and
paragraph-level components that automatically generate text for
certain tasks, promoting information reuse over duplication. I
supplemented my concept with internal documentation to facilitate the
adoption of the improved documentation structure.
Problem
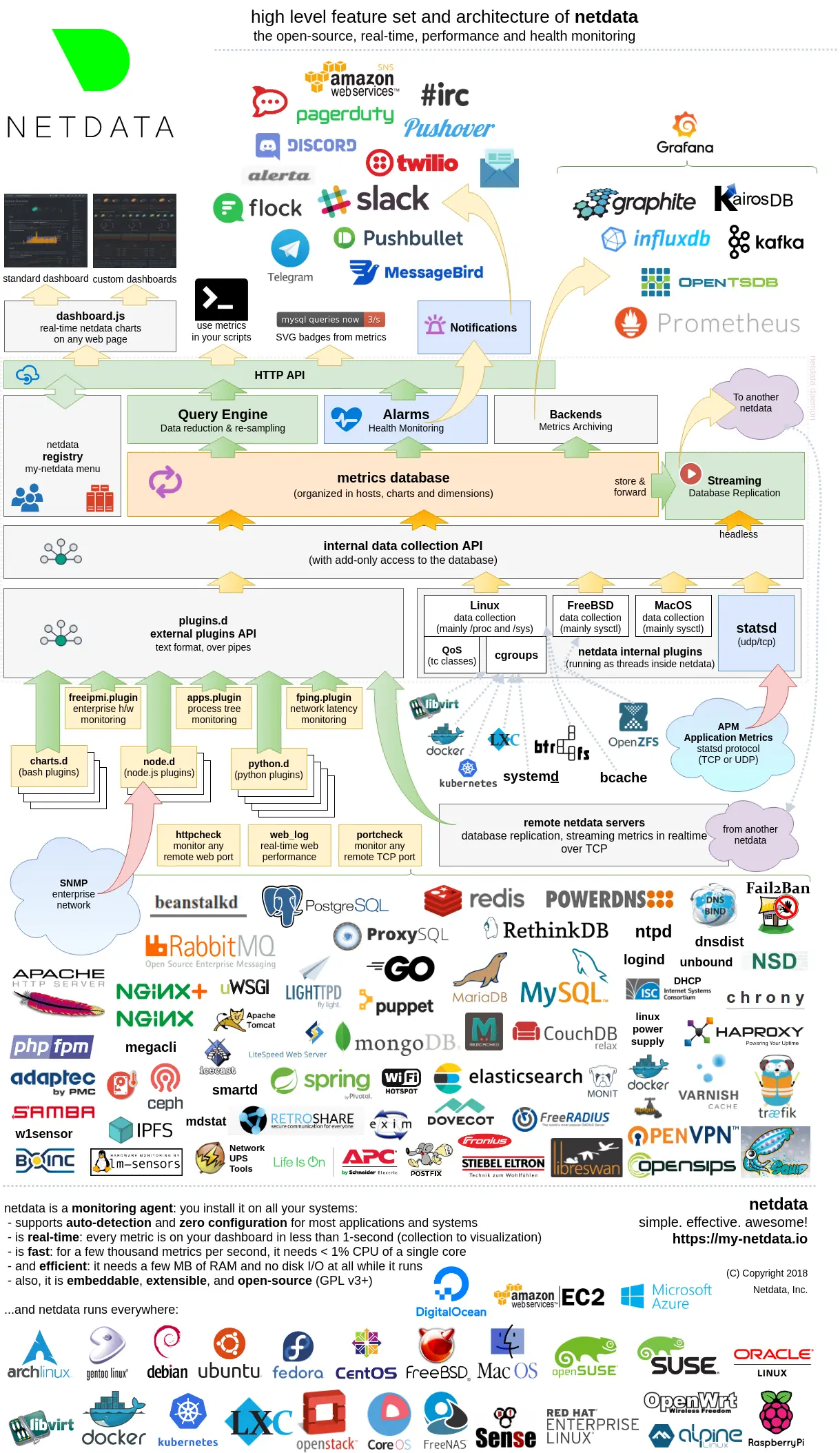
Fig. 1 - An overview of platforms Netdata integrates with. Source:
Netdata on Github
Netdata is an open-source system health monitoring
software you can install on your devices to monitor your hardware. To
be able to collect data from a wide array of applications, Netdata
provides numerous plugins and collectors - and a documentation page
for each of them (~200 in total).
Netdata's documentation needed to match the quick growth of the
company. A lot of content was written without a long-term strategy in
mind, giving rise to the following problems:
Page duplicates and outdated pages that were still online.
Inconsistent page structure with varying degrees of detail.
Complex documentation setup, making it complicated for the community
and non-tech writing staff to contribute.
Goals
The goals of my initiative were to improve documentation maintainability
and usability by:
Establishing a consistent structure on the page and paragraph level
Increasing the information density and standardizing the collector
pages (which make up ⅔ of the overall documentation)
Reducing content duplications and change drift by establishing a
single source of truth
Whenever I audit documentation, I focus on two areas:
Quantitative audit
What content is in the documentation set? Are there duplicates? Is
something missing? This part of the audit is to take inventory of the
content and assess it from a bird's eye view.
Qualitative audit Assesses the quality of the
documentation by analyzing a selection of representative examples.
This is the microscopic view to find out how content on the page- and
paragraph-level needs to be optimized.
Quantitative audit
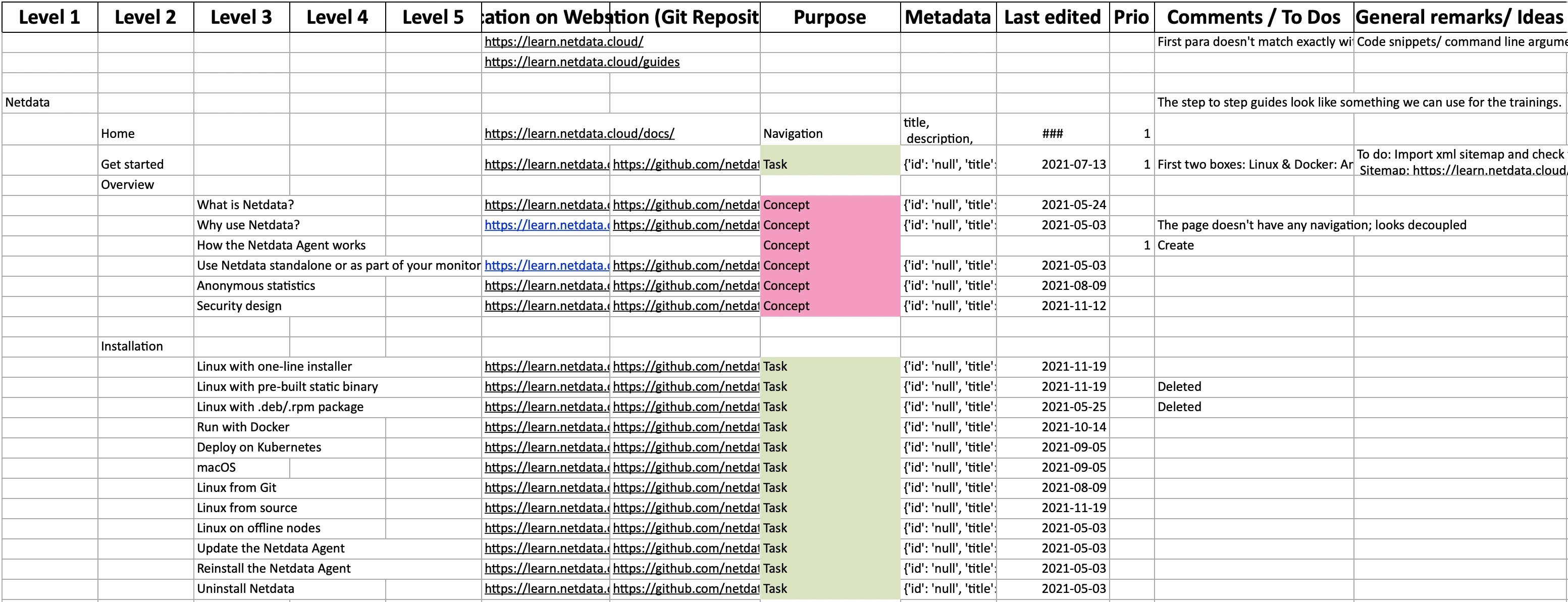
When I am looking at the bigger picture, I usually work with a
spreadsheet representation of the sitemap. I look at each page briefly
to determine its purpose and note it down using the DITA classification
(Task, Concept, Reference). Very often, I encounter pages that mix each
of these topic types. For these, I will add a note of what was mixed to
spot potential patterns later on.
The spreadsheet is a great tool to identify duplicates or topical
intersections and helps with making informed decisions about information
architecture.
Fig. 2 - Quantitative audit table
Qualitative audit
When I am analyzing the quality of a document, I often reach to one or
more of the following tools in my toolbox:
Performing a content audit is a lot of work, but it pays off as it
allows you to make informed decisions about your content. The audit
revealed three major issues:
Duplicate content
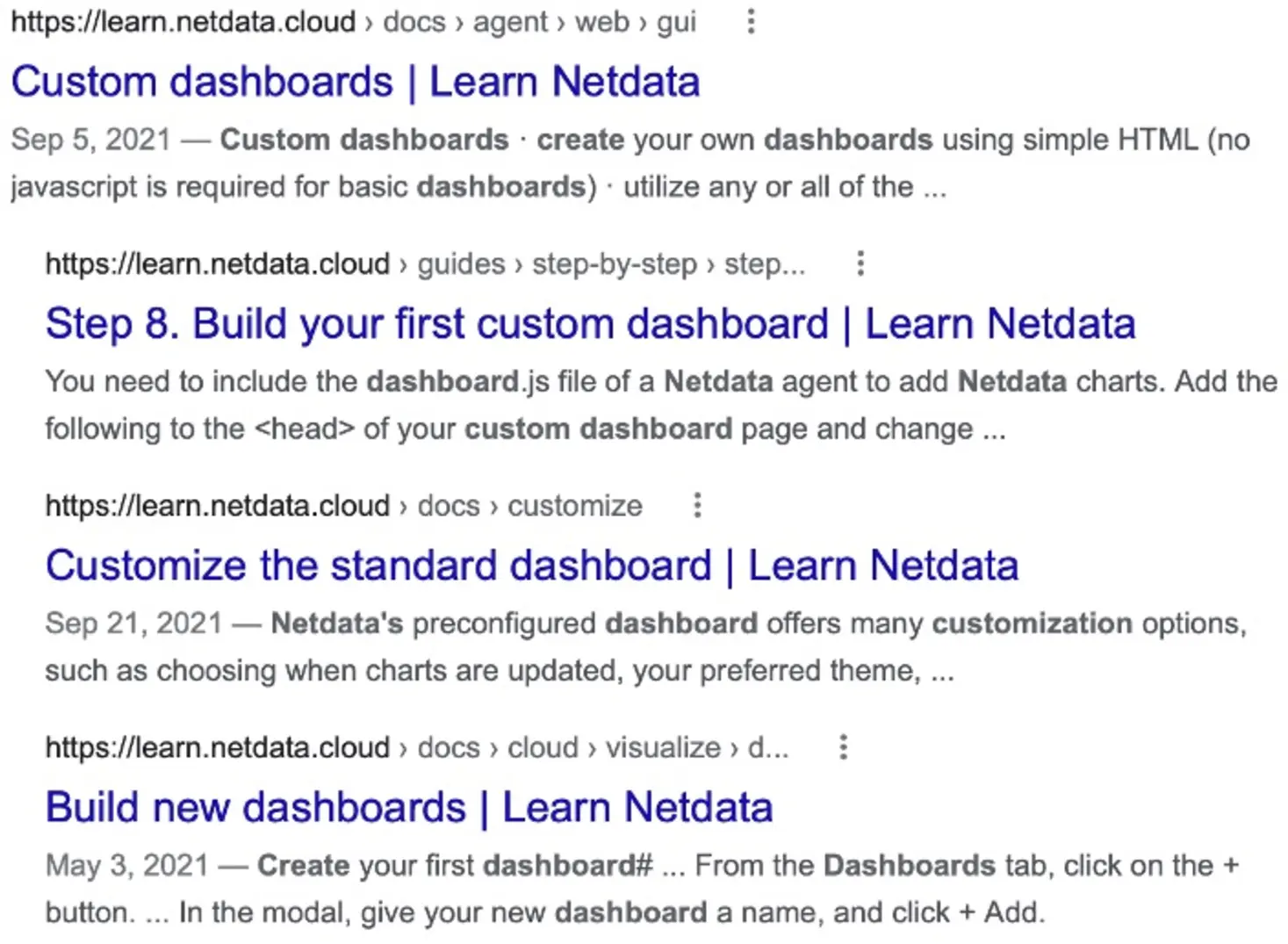
Let's assume that our user just downloaded Netdata and sees the
dashboard for the first time. They might want to customize the
dashboard and search for more information on Google. The good
news: Netdata's pages rank at the top. The bad news: The user is
confronted with four possible solutions to their problem instead of
one, possibly decreasing the chances that they will find the
information they need.
Fig. 4 - Many duplicates with similar information
Inconsistent Collector pages
Looking through most of the collector pages revealed that the pages
structured information inconsistently but there were some topics that
recurred, like
Configuration and Troubleshooting. Based on these
recurrences, I built a document model that would propose a set of
needed and optional sections.
Maintainability
The Netdata documentation comprises over 300 hand-written Markdown
files. Without a documentation strategy, content will naturally be
duplicated. However, updating and maintaining documentation becomes
more cumbersome as the count of monolithic pages increases.
Possible solution
All of these shortcomings can benefit from a
single source of truth. A single source of truth means
that you store and maintain content in one place. When we talk about
single-sourcing, we also need to store content in a modular way, so we
can embed useful information, instead of copying and pasting it into
other documents. That way, whenever we need to update the content, we do
it once and all embedded instances get updated automatically.
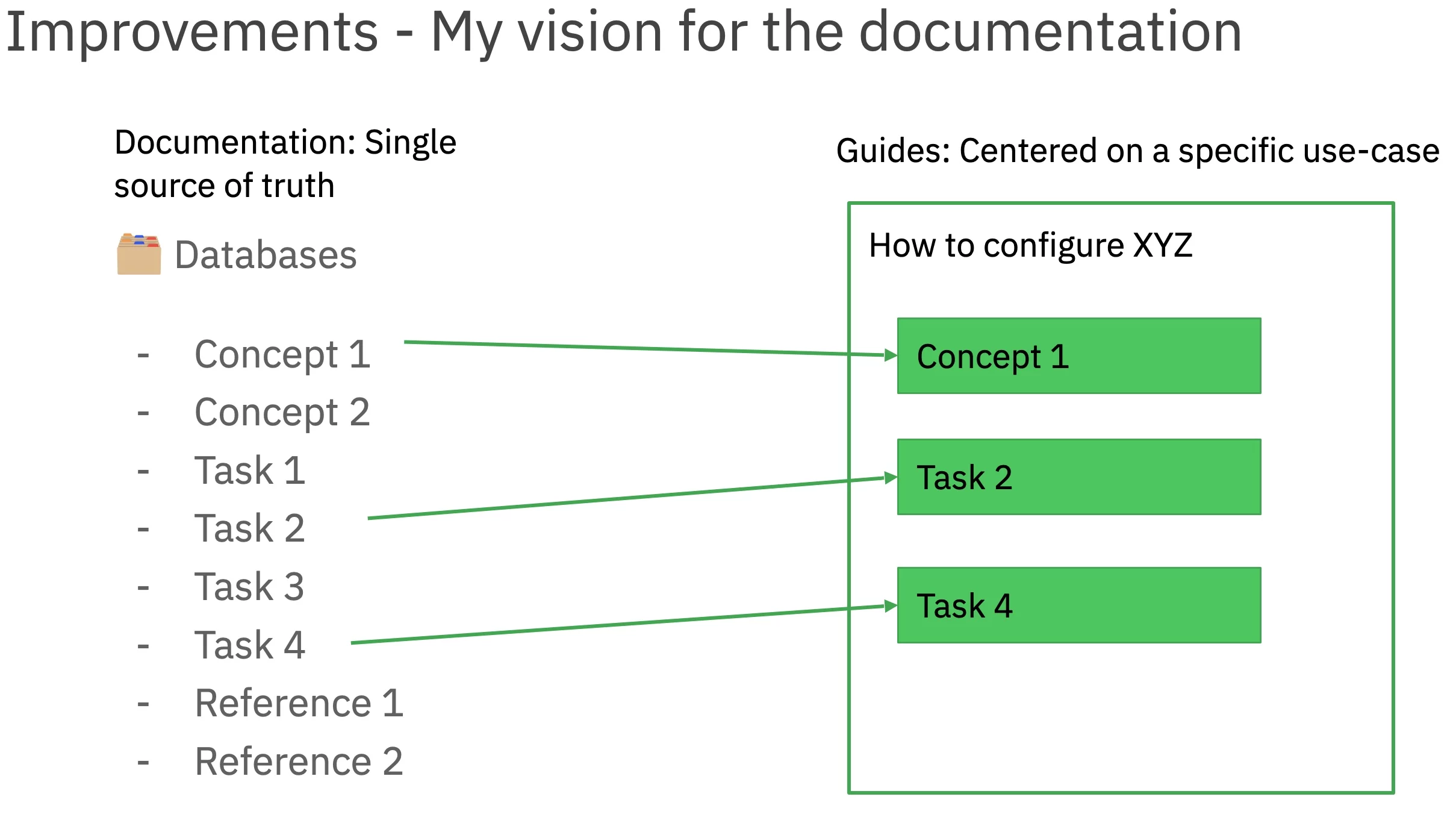
The figure below illustrates what this could look like: The
documentation is the single source of truth and contains all information
about a feature, e.g. databases. When you now want to create a new page
that is tailored to a specific use case, you can reassemble the parts as
needed - like assembling Lego!
Fig. 5 - What a reuse strategy can look like
Now, if adjacent departments like marketing, training, etc. use the same
input formats, you could make content consistent across departments.
That way, content could be created, used, and maintained in sync with
the product life cycle.
Creating Templates
The audit showed that I could standardize nearly 200 pages with one
template.
I started drafting a template and discussing it with my peers. I
determined which sections were always required and which were optional.
Side note: Ideally, you would define such a document structure in an XML
schema, but Markdown doesn't allow for document validation, which means
you need to train the writers to ensure the structure.
The final template featured the use of "components" which are modular
bits of code you can insert into an MDX file. MDX blends together
Markdown and JSX code, a language used by the frontend framework React.
I created components to generate standardized chunks of text. To make
the text customizable, you can pass in a variable that will get inserted
in the text.
For example:
While working at Netdata I relocated to the U.S. for personal reasons.
Unfortunately, I had to part ways in the process. There was still a lot
to do before I left, so I to prepared a diligent handover, including the
creation of knowledge sharing sessions, recorded trainings, and
extensive documentation. This allowed my team to continue implementing
the project.
Challenges
Establishing a single source of truth
The reason why a single source of truth is desirable, is to reduce
inconsistencies and make content more manageable. However, to really
leverage a single source of truth, you need to have bits of
highly-structured content; Markdown files are the opposite of that being
loosely written monolithic documents lacking extensive metadata.
Markdown itself doesn't support the technical mechanisms needed to
implement a sophisticated reuse concept. To leverage at least some
benefits of content reuse, I created "components" based on JSX, as
described
above.
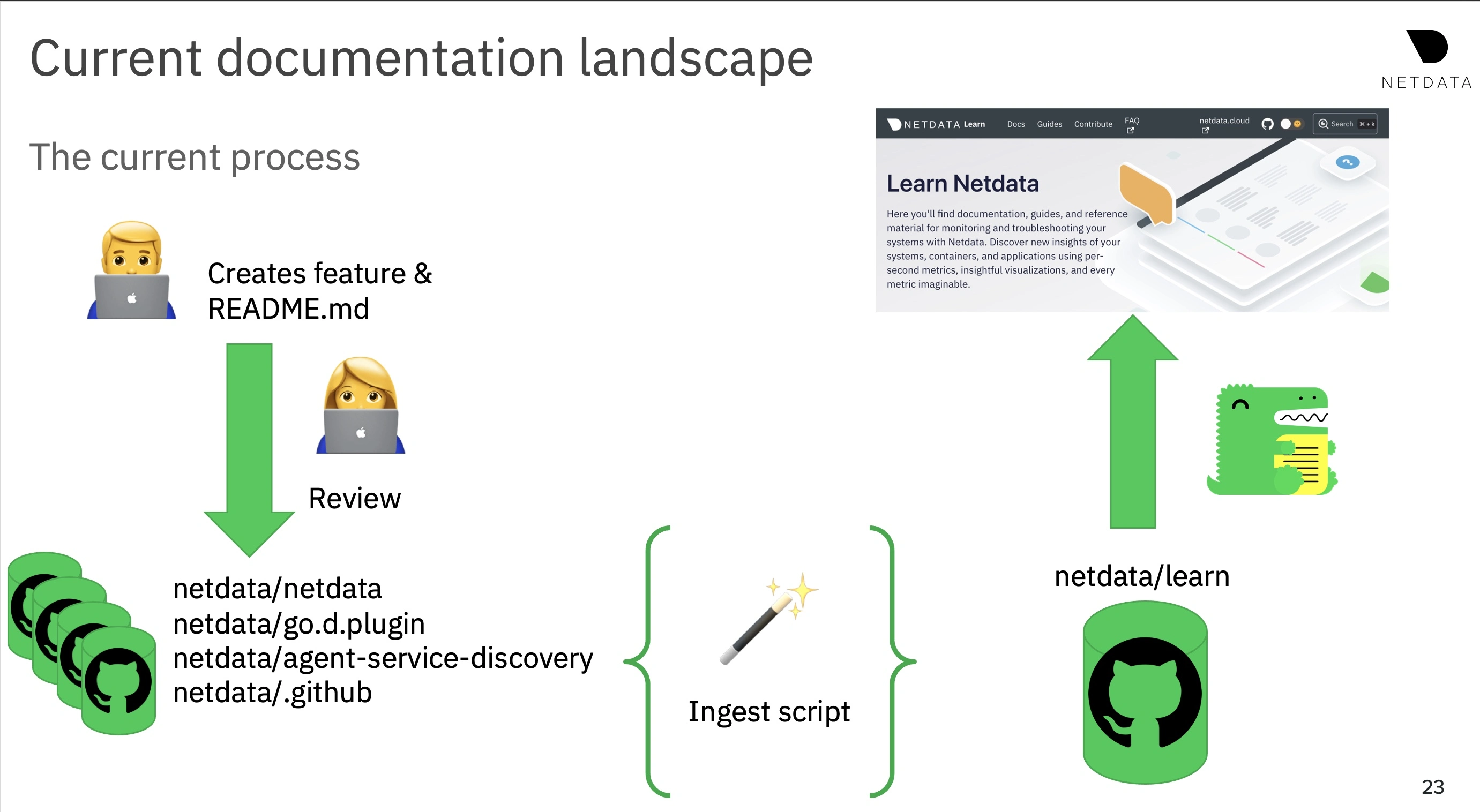
Another reason why we weren't able to easily implement a single source
of truth was the documentation setup (see fig. 6). The docs were set up
in a way that prioritized low friction for the engineers, not the tech
writers. Separating the static site generator from the documentation
repositories meant that unless you had a lot of context, you didn't know
if you were working with a copy or the original file in the
netdata/learn repository.
Fig. 6 - Documentation setup at Netdata
Accommodating different audience needs
Together with my manager and senior engineers we discussed the
trade-offs between readable source code and a good UX on our
documentation website. Using components meant that maintaining the
documentation would become easier. But using a static site generator to
resolve the component and render the content meant that it was difficult
to understand the Markdown files by themselves.
We decided that we wanted our documentation website to be the main
format of delivery, as it allows us to create interactive code samples,
and other features. The website also allowed us to gather data about
user behavior to make further improvements to our content.
Impact
Even though I am no longer with the company, I am sure that the
initiative will stabilize Netdata's documentation set and enable them to
produce content more easily.
I've introduced the single source of truth and reuse paradigm, and laid
out what the future of Netdata's documentation could look like. Single
sourcing content unlocks synergies between departments - Netdata's brand
identity, voice and tone would stay consistent across departments while
keeping information up-to-date more easily.
My manager used to say "We build the tracks as the train moves forward."
While the vision of a unified content strategy is a tall order, I showed
one potential way to lay down some tracks using their existing tech
stack.